What is Apache Kafka?
What is Apache Kafka all about? This program that virtually every major (German) car manufacturer uses? This software that has allowed us to travel across Europe with our training sessions and workshops and get to know many different industries - from banks, insurance companies, logistics service providers, internet startups, retail chains to law enforcement agencies? Why do so many different companies use Apache Kafka?


By Alexander Kropp and Anatoly Zelenin

Use Cases
We divide Apache Kafka’s applications into two categories: The first group of use cases is what Kafka was originally designed for. Apache Kafka was initially developed at LinkedIn to move all events occurring on the LinkedIn website into the central data warehouse. LinkedIn was looking for a scalable and high-performance messaging system that could handle very high loads, and ultimately created Kafka for this purpose. Today, many companies use Kafka to move large amounts of data from point A to point B. The focus is often on the required performance, Kafka’s scalability, but also on the reliability that Kafka provides for message delivery and persistence.
However, one of the core ideas that distinguishes Kafka from classical messaging systems is that Kafka persists data. This allows us to store data in Kafka and read written data not only multiple times but also hours, days, or even months after the data was written.
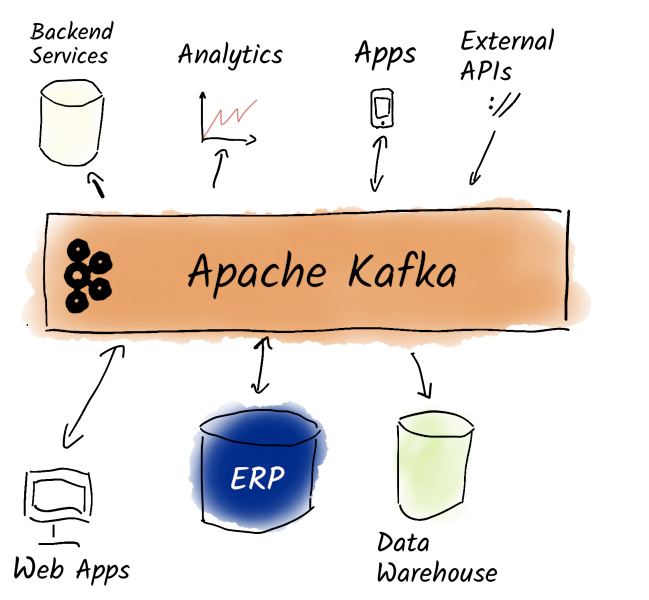
This enables the second category of Apache Kafka use cases: More and more companies are using Kafka as a central tool not just to exchange data between various services and applications, but to use Kafka as a central nervous system for data within companies. But what do we mean when we say that Kafka can be the central nervous system for data? The vision is that every event that occurs in a company is stored in Kafka. Any other service (that has the necessary permissions) can now react to this event asynchronously and process it further:
Figure 1. Kafka as a central nervous system for data in the company. Every event that occurs in the company is stored in Kafka. Other services can react to these events asynchronously and process them further.
Old and New World
For example, we see in many companies the trend of separation between so-called legacy systems, which are essential for existing business processes and business models, and the so-called New World, where new services are developed using agile methods that also need to be implemented in software. Often, companies use Kafka not only to act as an interface between old and new systems but also to enable new services to exchange messages with each other.
This is because legacy systems are often not equipped to meet the new requirements of our customers. Batch systems cannot satisfy the demand for information that should always be "immediately" available. Who wants to wait a day or even several weeks for their account balance to update after a credit card transaction? We now expect to be able to track our packages in real-time. Modern cars produce vast amounts of data that need to be sent to headquarters and analyzed, especially in preparation for autonomous driving. Kafka can help all these companies move from batch-oriented processing to (near) real-time data processing.
But the way we write software is also changing. Instead of putting more and more functionality into monolithic services and then connecting these few monoliths through integration, we break our services into microservices to reduce dependencies between teams, among other things. However, this requires a way of exchanging data that is as asynchronous as possible. This allows services to continue functioning independently, even if one service is under maintenance. We need communication methods that allow data formats in one service to evolve independently of other services. Apache Kafka can help us here as well.
Another trend, primarily triggered by virtualization and the increasingly widespread use of cloud architectures, is the move away from specialized hardware. Unlike other messaging systems, there are no Kafka appliances. Kafka runs on standard hardware and doesn’t require fault-tolerant systems. Kafka itself is designed to handle partial system failures well. This makes message delivery reliable, even when there might be chaos in our data center.
But how does Kafka achieve this reliability and performance? How can we use Kafka for our use cases, and what should we consider when operating Kafka? We want to give you answers to these questions and much more on the journey through this book.
The book is available directly from us, from the Manning, Amazon, and book stores. For support and questions about Kafka, just write to us or book a call.
About Alexander Kropp
Alexander Kropp has been a passionate computer scientist since childhood and has been programming since he was 10 years old. As a researcher and consultant, Alexander has been supporting renowned companies in digitalization and prototype development for a decade. In parallel, he works as a lecturer and trainer in the cloud environment.
About Anatoly Zelenin
Hi, I’m Anatoly! I love to spark that twinkle in people’s eyes. As an Apache Kafka expert and book author, I’ve been bringing IT to life for over a decade—with passion instead of boredom, with real experiences instead of endless slides.
Continue reading

Apache Kafka at a Glance
Companies leverage Apache Kafka to make decisions in near-real-time. This data hub and event streaming platform enables answers at the moment questions arise, helping organizations shift from waiting to acting
Read more
First Steps with Apache Kafka
Before we dive into all the details, let's launch our Apache Kafka rocket together and see how it performs on its first test flight. After all, every rocket science has to start somewhere. In this spirit: 3, 2, 1... Ignition
Read moreWe believe in a world where companies make better decisions with real-time data, act sustainably, and actively shape their digital future.
Copyright 2026, All Right Reserved
Contact
Address
Commit to Flow GmbH
Wiener Platz 11
01069 Dresden