Schema Management in Kafka
In this post, you'll learn how explicit schemas help you avoid potential chaos in Kafka and how schema registries support this.
In my Apache Kafka Lunch and Learn sessions, participants of my Kafka courses can learn about additional interesting topics, even after the training is officially over. This blog post is an edited transcript of the video. The practical exercises are exclusively available to participants. If you would like to try them out, please feel free to contact me.
Data always has a schema. The question is only whether you and the other development teams know about it, whether the schemas are implicitly stored somewhere in the code and placed in JSON strings, or explicitly written down, coordinated, and shared with other teams.
Schemas vs. Data Formats
It’s important to understand that schemas are not the same as data formats. The discussion around schemas is independent of the data format used and usually independent of the technology employed. Whether JSON, Avro, Protobuf, or a custom binary protocol: nothing works without a schema. In relational databases, the topic of schemas is relatively simple: all services that interact with the database must work with the same schema, namely the current database structure.
Schema Evolution
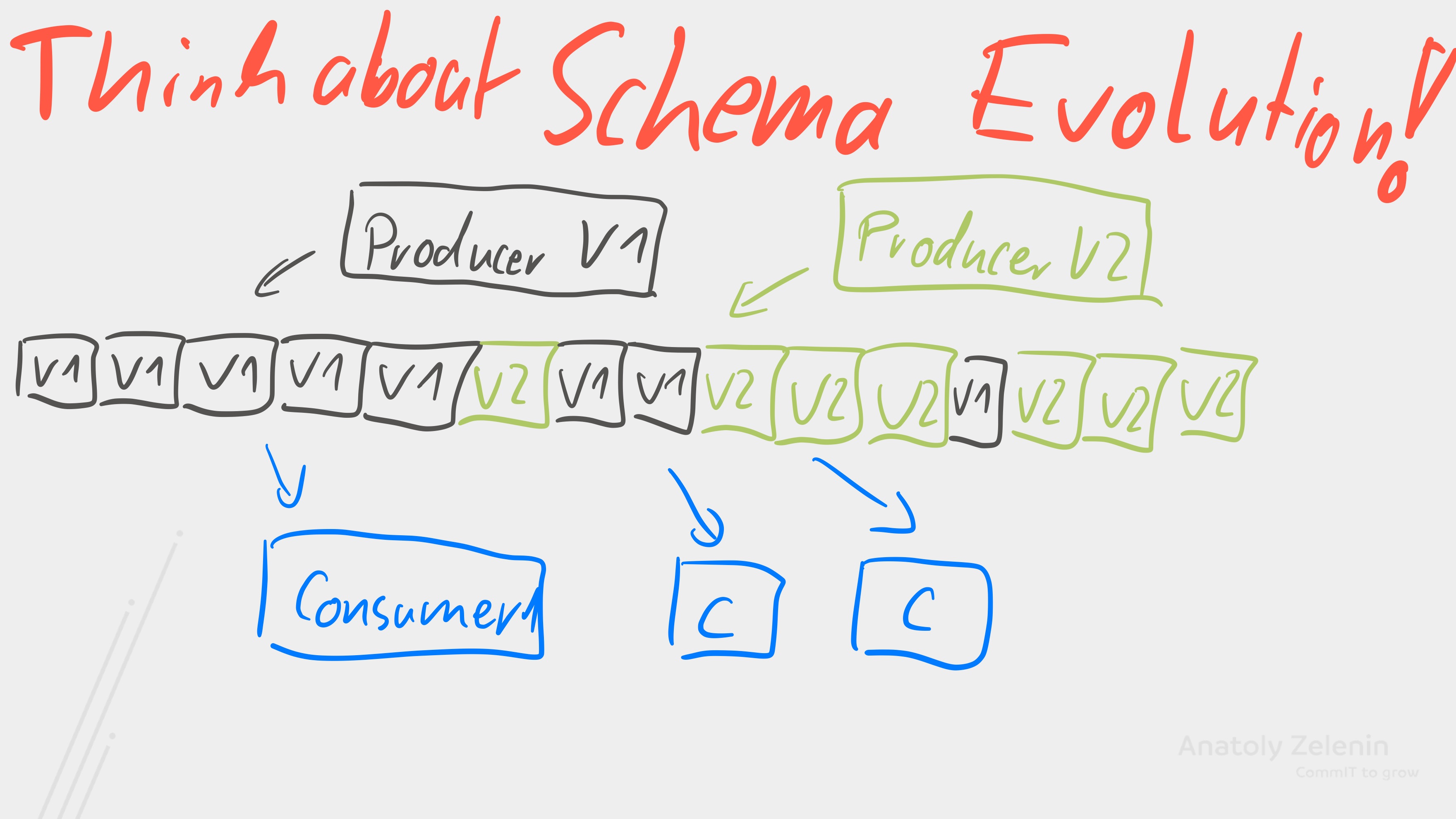
As we know, migrations are anything but trivial. Especially when they break compatibility. With Kafka, the situation is complicated by the fact that it’s a log and data can remain in Kafka for a long time. This means it can happen, and often will happen, that we have different schema versions in a topic. It may even occur that there is a period during which different producers write different schema versions.
Figure 1. In Kafka, it can happen that data in a topic exists in different schema versions.
This is not inherently problematic, but we need to think ahead about how our consumers should handle this. And so we come to one of the most important topics in Kafka’s schema world: schema evolution, because data will certainly change and the question is how we deal with it.
Update Sequences
| Compatibility | Consumer & Data | Update Strategy |
|---|---|---|
Forward |
Old Consumers – New Data |
1. Producer, 2. Consumer |
Backward |
New Consumers – Old Data |
1. Consumer, 2. Producer |
Bidirectional |
Old/New Consumers – Old/New Data |
Doesn’t matter |
None |
Consumer = Data |
Simultaneously |
First, we should think about compatibility. Should our consumers be forward compatible, meaning old consumers can read newer data? Or do we need backward compatibility, then current consumers must be able to read old data, or do we even need to be compatible in both directions, then it doesn’t matter which direction we look: every consumer must be able to handle all data. Sometimes it’s also okay to say there is no compatibility. Then things go wrong when consumers receive data that doesn’t match their version. Additionally, we need to think about our update strategies. If we don’t need compatibility, then we have to update consumers and producers simultaneously. We achieve this, for example, by stopping the producers, letting the consumers process all data, then deploying the producers in a new version and deploying the consumers in a new version at the same time. With forward compatibility, the producers are updated first and then the consumers. With backward compatibility, it’s exactly the opposite: first consumers, then producers. And if we want to be compatible in both directions, it doesn’t matter what gets updated first.
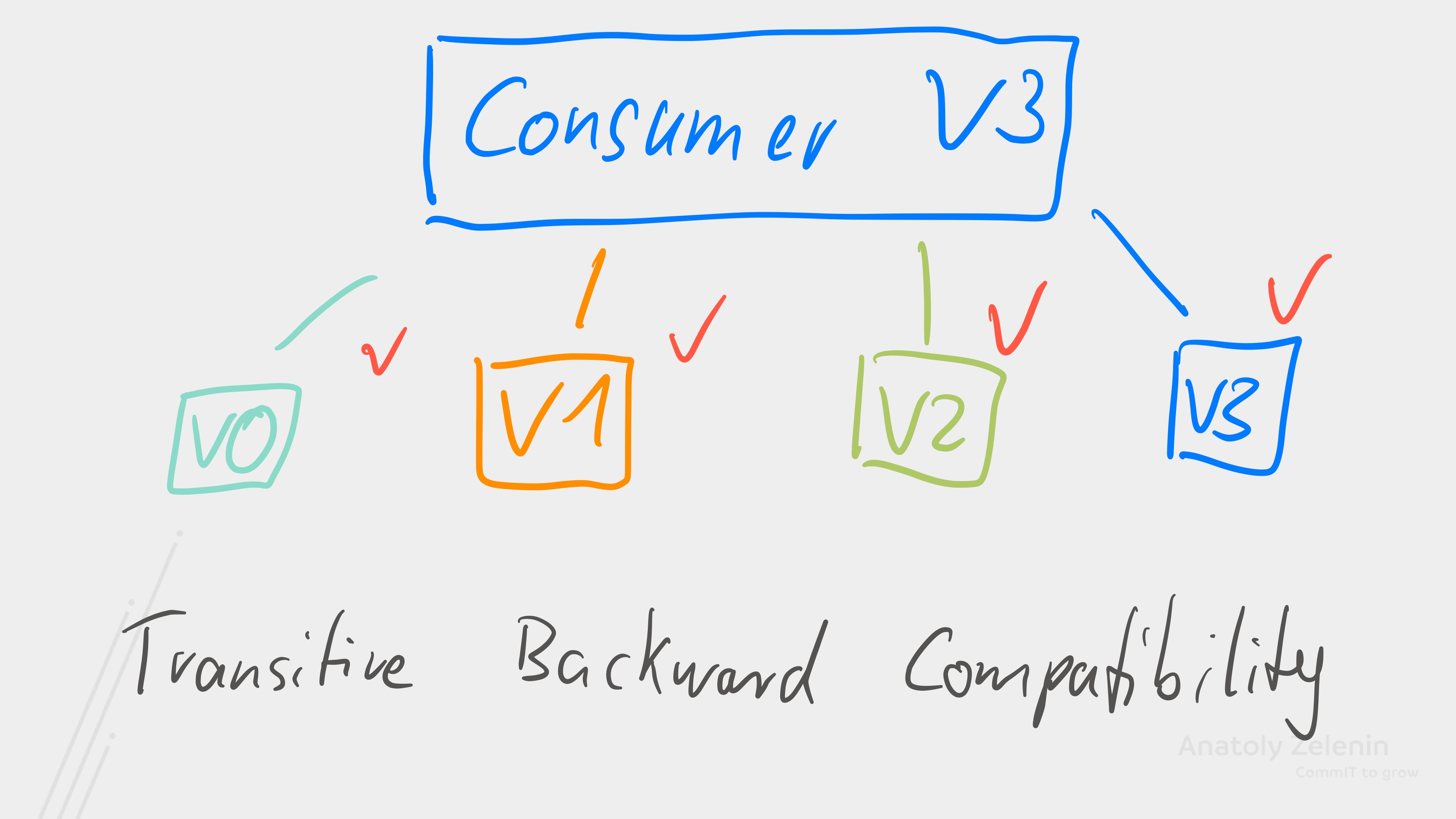
Figure 2. A transitive backward compatible consumer can also read old data.
Another point we should pay attention to concerns transitivity: is it sufficient for the consumer to read only the latest version, or do we need the consumer to be able to read all previous versions of the data? For this, the consumer must be transitively backward compatible.
Compatibility
But let’s use an example: Let’s take the three compatibility types – forward, backward, and bidirectional. And now we perform one of the following four operations: We add a required field or delete a required field. We add an optional field or delete an optional field.
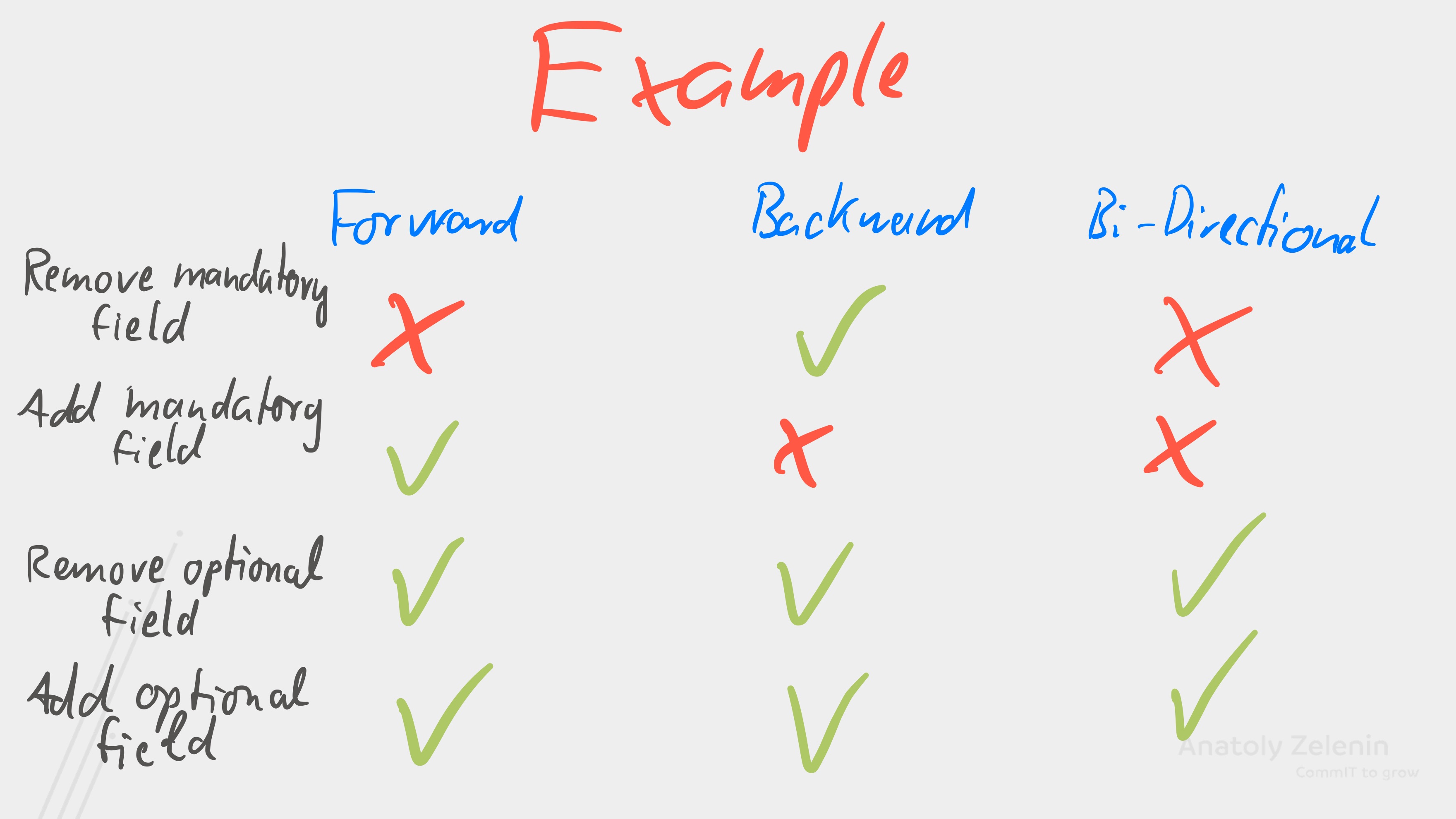
Figure 3. With optional fields, we can even achieve full compatibility
Let’s look at this: We can delete required fields if we are backward compatible, but not forward compatible. Required fields can only be added with forward compatibility, and optional fields can always be added or removed without restricting compatibility. When we use schema registries in Kafka, we can set the desired compatibility.
Schema Registries
Whether you end up using a schema registry or not, here’s a recommendation I give to my consulting clients: You need a central place where you document, manage, and share schemas. Exactly how you do this depends on your circumstances. Of course, this can be a page in Confluence or in another wiki. But you’re usually better off managing schemas in Git and then using a schema registry. My opinion is that there should ideally be a Git-based process to ensure governance, and the schemas should then be deployed to the schema registry via CI/CD pipeline. Under no circumstances should it be as is standard: deployed to production via code in your Java code.
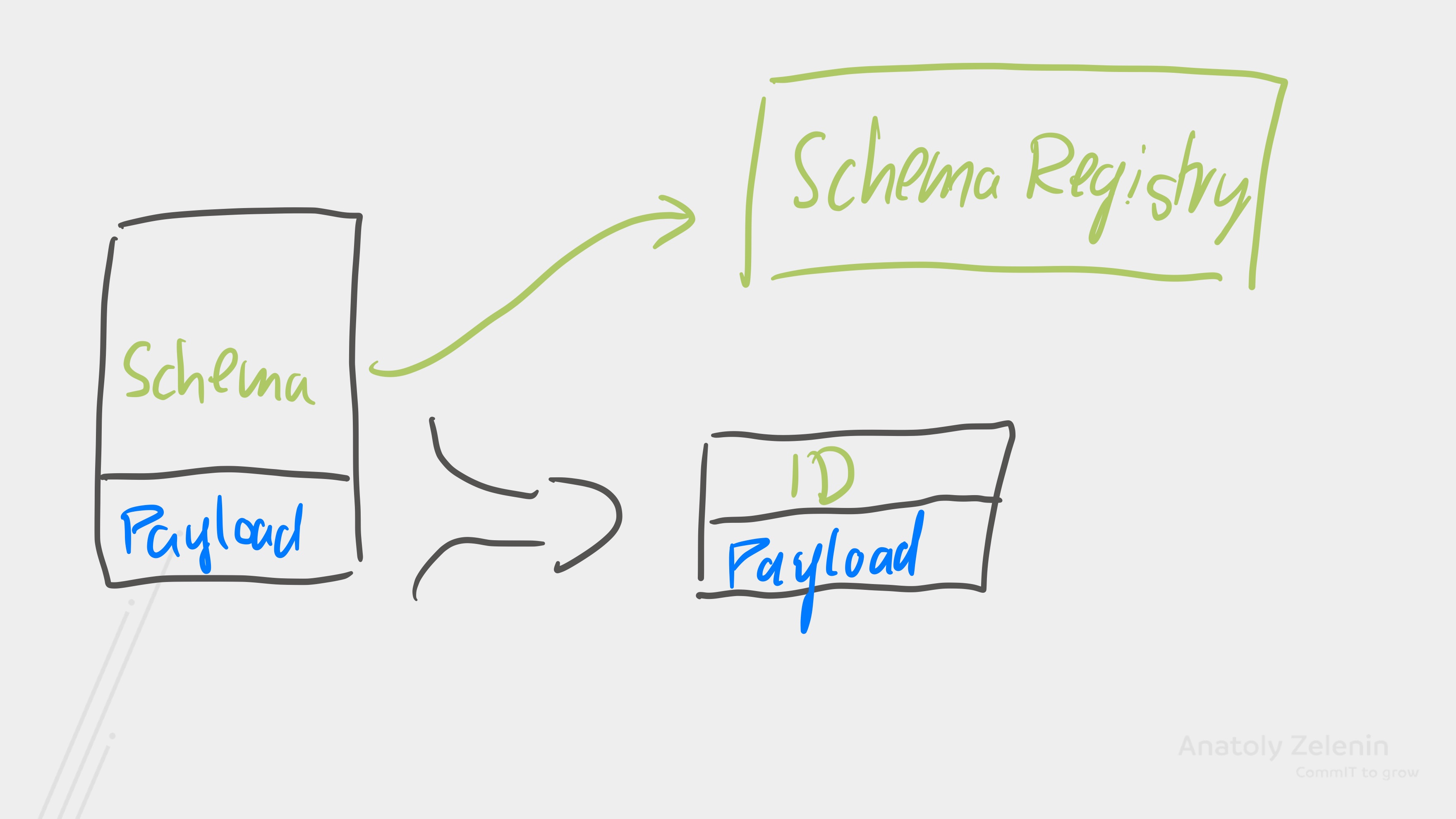
Figure 4. In Avro, the schema often takes up more storage than the actual message. A schema registry solves this problem.
Especially when we use Avro, using a schema registry is very sensible. Instead of sending the schema with every message, we store the schema in the schema registry and the producer only writes the ID of the schema in the message, thus drastically reducing the overhead, but it’s also useful with other data formats. With JSON-Schema, Protobuf, etc.
Different Schema Registries
I’m aware of three schema registries. The probably best-known is the Confluent Schema Registry, which is also the original, and if you’re already using Confluent, then this is the most sensible choice. If you’re looking for a schema registry with a proper open-source license, Aiven’s Karapace is a good choice. This is API compatible with Confluent’s registry. And we also use it in the lab. Another very exciting schema registry is Apicurio. Apicurio supports not only Kafka but also different API schema formats like Async API, Open API, and so on. Going into depth on this would be beyond the scope of this module.
Have fun trying it out!

About Anatoly Zelenin
Hi, I’m Anatoly! I love to spark that twinkle in people’s eyes. As an Apache Kafka expert and book author, I’ve been bringing IT to life for over a decade—with passion instead of boredom, with real experiences instead of endless slides.
Continue reading

Kafka: How to Produce Data Reliably
Want to ensure that not a single Kafka message gets lost? In this guide, I'll show you how to achieve maximum reliability when producing with the right configurations and what to do in case of errors.
Read more
Debezium: Change Data Capture for Apache Kafka
In this post, we'll show you how to reliably import data from various databases into Kafka in near real-time using Debezium. Debezium is a Kafka Connect plugin that connects to the internal log of databases to capture changes and write them to Kafka.
Read moreWe believe in a world where companies make better decisions with real-time data, act sustainably, and actively shape their digital future.
Copyright 2026, All Right Reserved
Contact
Address
Commit to Flow GmbH
Wiener Platz 11
01069 Dresden